受用户的需求,特此撰写本文。
爬取网页是根据每个网站的设计特点专门制定爬取计划,没有绝对的统一脚本可以完成,市面上的爬虫软件,基本上是需要用户自己选取内容爬取,之后软件自己会记录网站特征,之后获取内容的。
如果网站的源码是非常常规的,我们本节内容就可以搞定!
如果网站的内容是动态加载,那需要采用Selenium这种工具来完成!(本文不讲)
被测网页:Ether.Fi Pledges $600M in Ether to Reinforce Omni Network (coingape.com)
如何判断网页内容是不是动态加载的,如图,左边就是动态加载的,而右边是常规
创建基础的网页爬取代码
import requests
# 目标网页的URL
url = 'http://example.com'
# 自定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 发送请求
response = requests.get(url, headers=headers)
# 检查响应状态码
if response.status_code == 200:
# 请求成功,打印网页内容
print(response.text)
else:
# 请求失败,打印状态码
print(f'请求失败,状态码: {response.status_code}')就是一个非常简单的get爬取,你需要把url改为你的目标网站
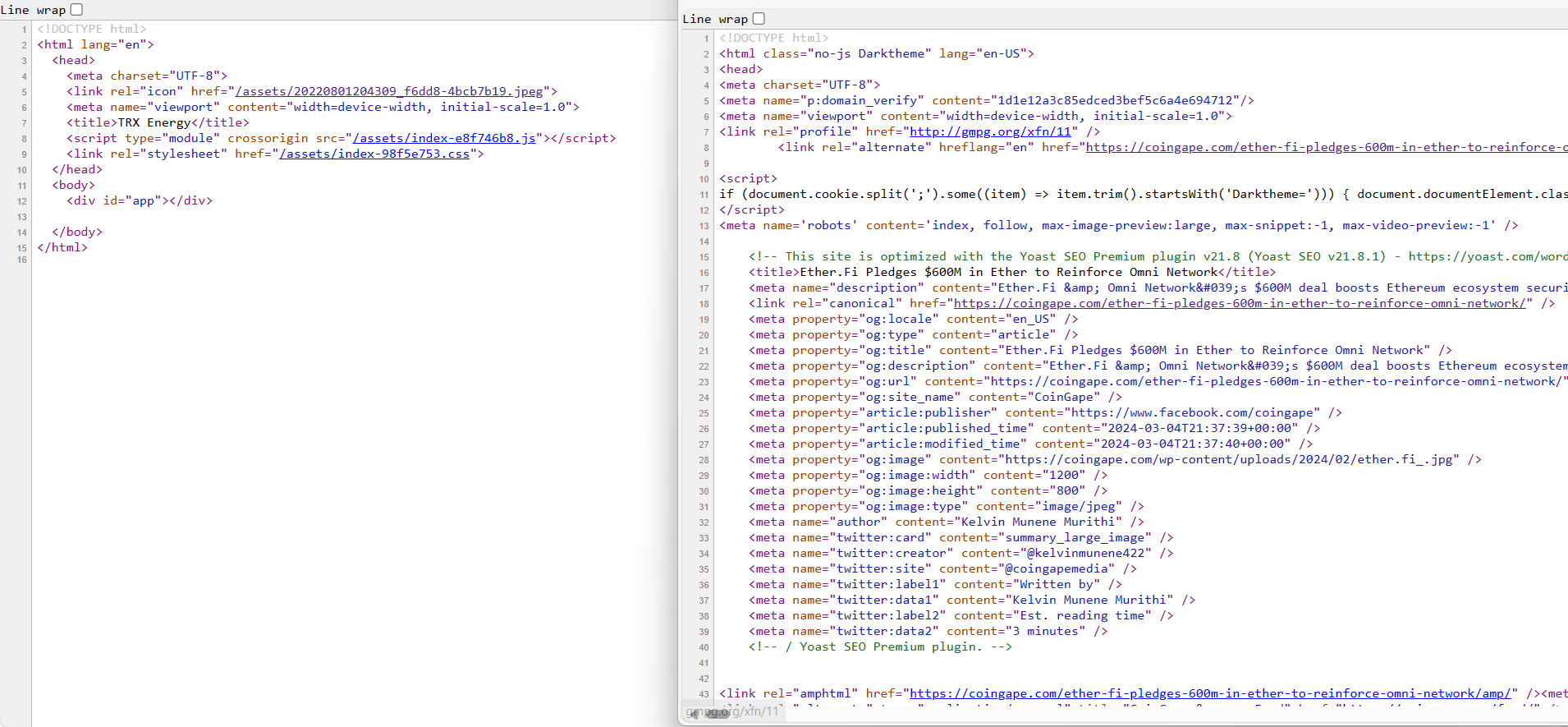
很快我们把网页内容爬取下来了,和我们打开网页源代码一样,这没有什么区别。
<!DOCTYPE html>
<html class="no-js Darktheme" lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="p:domain_verify" content="1d1e12a3c85edced3bef5c6a4e694712"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="profile" href="http://gmpg.org/xfn/11" />
<link rel="alternate" hreflang="en" href="https://coingape.com/ether-fi-pledges-600m-in-ether-to-reinforce-omni-network/" />
<script>
if (document.cookie.split(';').some((item) => item.trim().startsWith('Darktheme='))) { document.documentElement.classList.remove('Darktheme'); }
</script>
<meta name='robots' content='index, follow, max-image-preview:large, max-snippet:-1, max-video-preview:-1' />
<!-- This site is optimized with the Yoast SEO Premium plugin v21.8 (Yoast SEO v21.8.1) - https://yoast.com/wordpress/plugins/seo/ -->
<title>Ether.Fi Pledges $600M in Ether to Reinforce Omni Network</title>
<meta name="description" content="Ether.Fi & Omni Network's $600M deal boosts Ethereum ecosystem security & interoperability, aiming for stronger blockchain stability." />
<link rel="canonical" href="https://coingape.com/ether-fi-pledges-600m-in-ether-to-reinforce-omni-network/" />
<meta property="og:locale" content="en_US" />
<meta property="og:type" content="article" />
<meta property="og:title" content="Ether.Fi Pledges $600M in Ether to Reinforce Omni Network" />选定元素爬取之后把内容上传到指定数据库
光爬取网站全部内容是不足的,范围太大,是不符合我们的要求。
依照我们的需求是需要爬取标题和内容,之后传递到数据库。
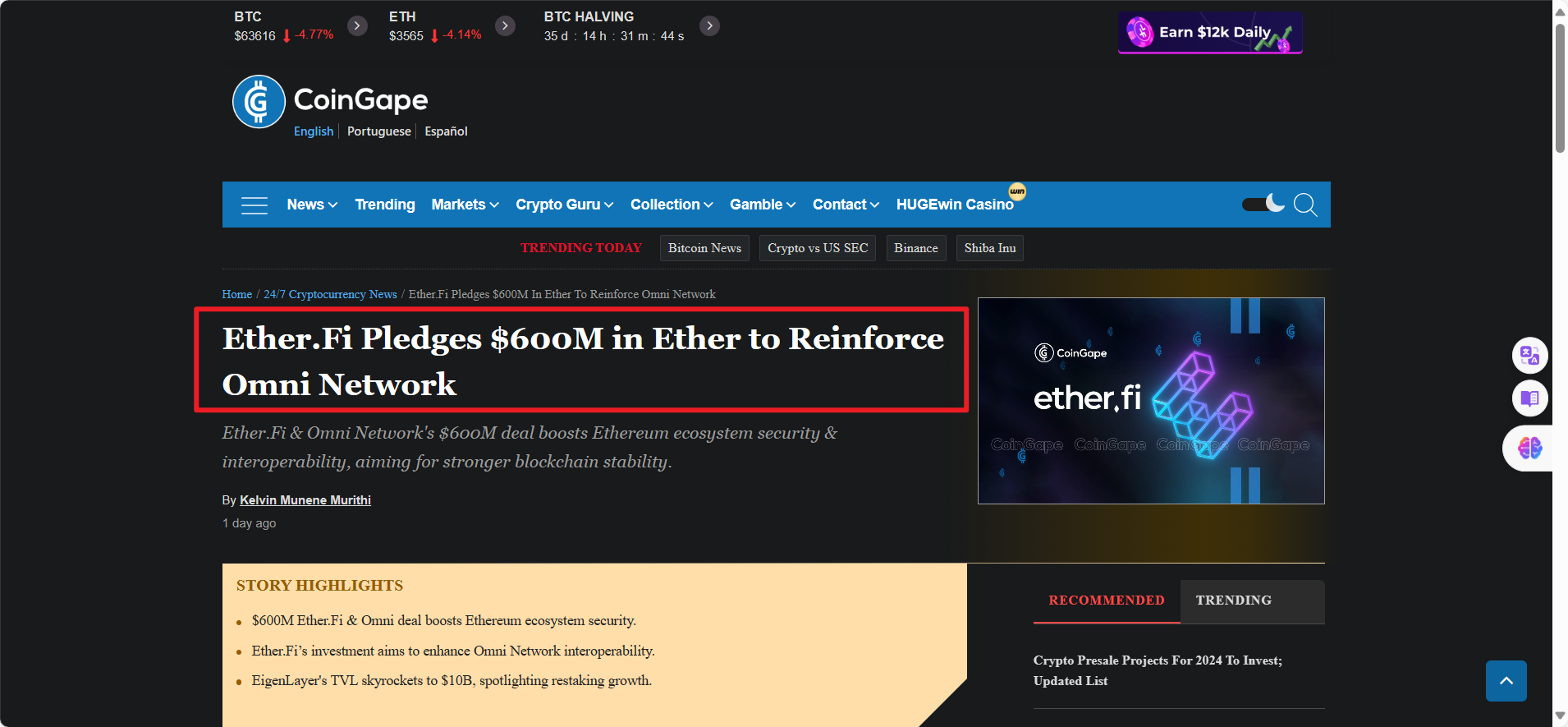

如果要实现精准爬取,我们需要获取我们内容所在的div和class类,采用这种定位方式,我们就可以拿到我们需要的内容。
首先鼠标停留在你的内容上方,之后右击选择检查,在浏览器的检查元素可以看到我们的内容。
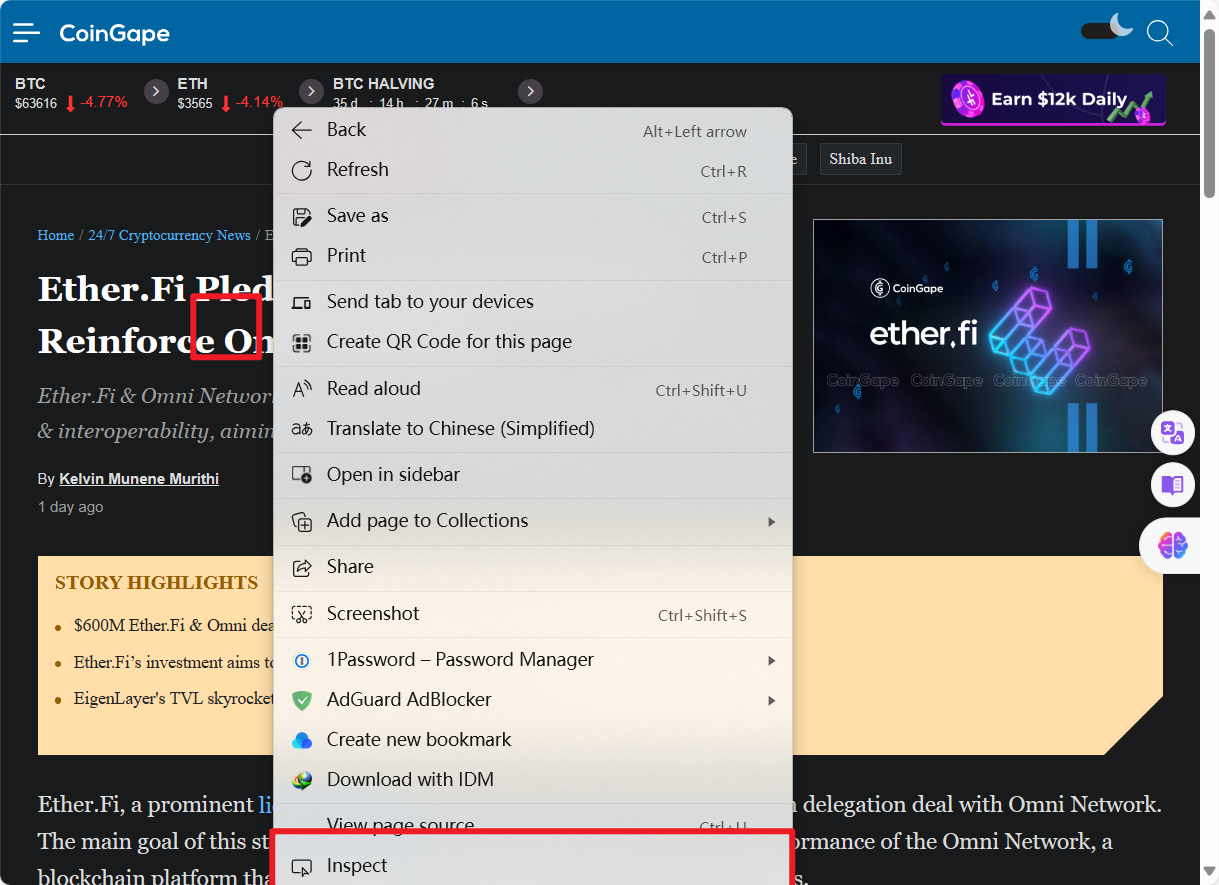
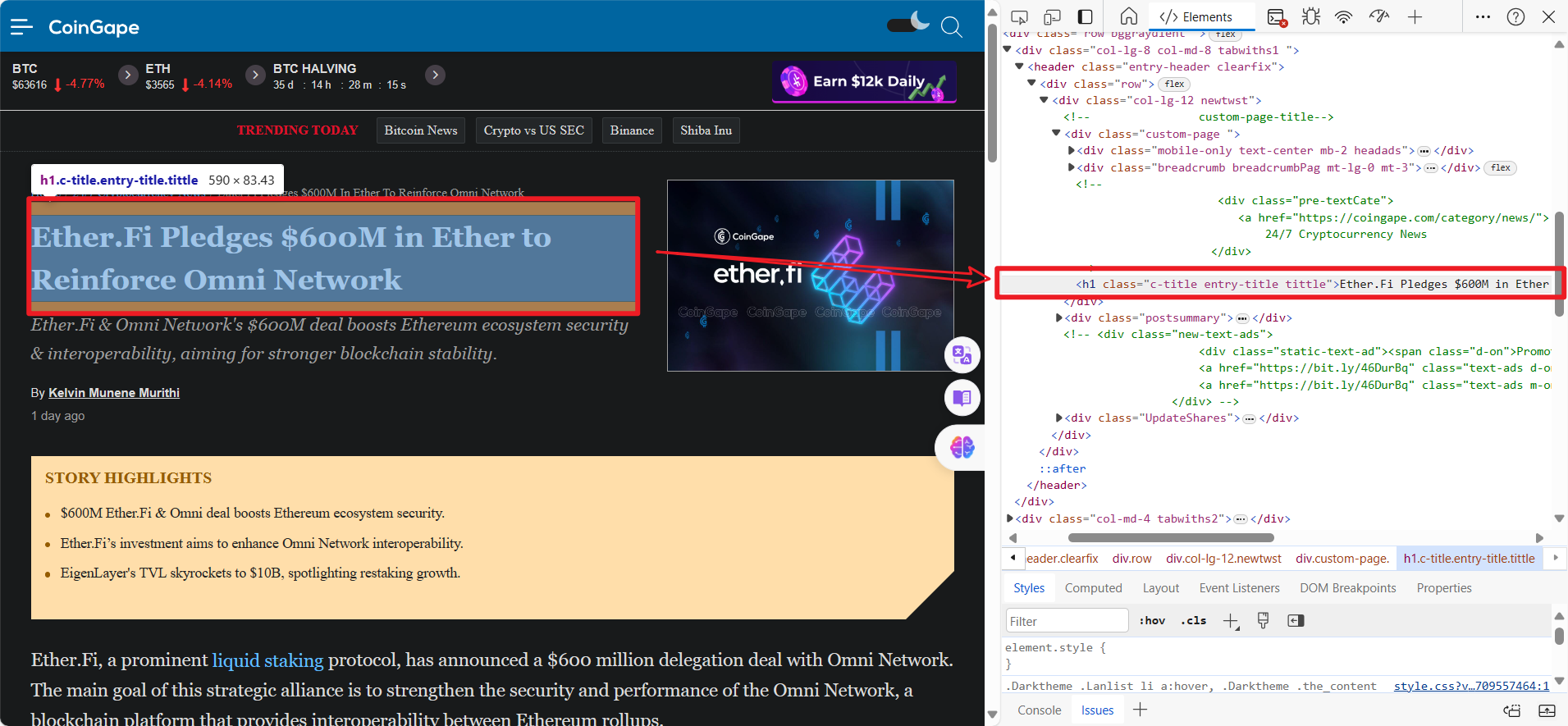
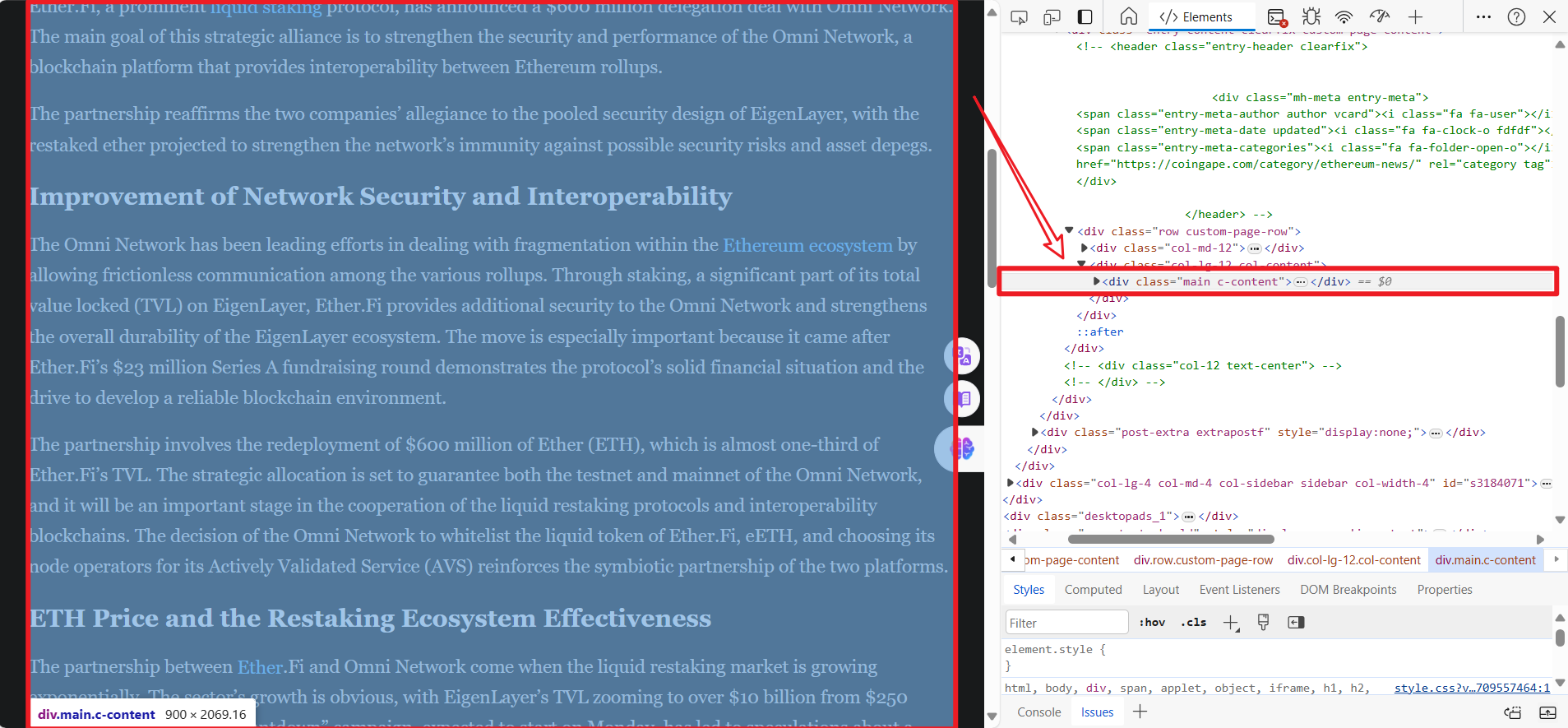
之后你需要获取类名和标签名称。
比如我们标题的类名是:c-title entry-title tittle
标签名称:h1
之后我们修正了我们代码:
from bs4 import BeautifulSoup
import requests
import mysql.connector
import json
# 加载并读取配置文件
with open('../config.json', 'r') as config_file:
config = json.load(config_file)
# 目标网页的URL
url = 'https://coingape.com/ether-fi-pledges-600m-in-ether-to-reinforce-omni-network/'
def insert_article(title, content):
connection = mysql.connector.connect(
host=config['host'], # 通常是 'localhost' 或 '127.0.0.1'
user=config['user'],
password=config['password'],
database=config['database']
)
cursor = connection.cursor()
query = "INSERT INTO articles (title, content) VALUES (%s, %s)"
cursor.execute(query, (title, content))
connection.commit()
cursor.close()
connection.close()
# 自定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 发送GET请求
response = requests.get(url, headers=headers)
# 确保请求成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到并打印标题
title = soup.find('h1', class_='c-title entry-title tittle').text.strip()
# title = asyncio.run(fanyi_mian(title))
title = title.replace('\r\n', ' ').replace('\n', ' ').replace('\r', ' ')
# 找到并打印文章内容
content = soup.find('div', class_='main c-content').text.strip()
content = content.replace('\r\n', ' ').replace('\n', ' ').replace('\r', ' ')
# content = asyncio.run(fanyi_mian(content))
insert_article(title, content)
else:
print(f'请求失败,状态码: {response.status_code}')在这里你需要修改一些内容:
根据我们上面获取标签和类名的方式,把代码修正一下,替换为你自己网站的。
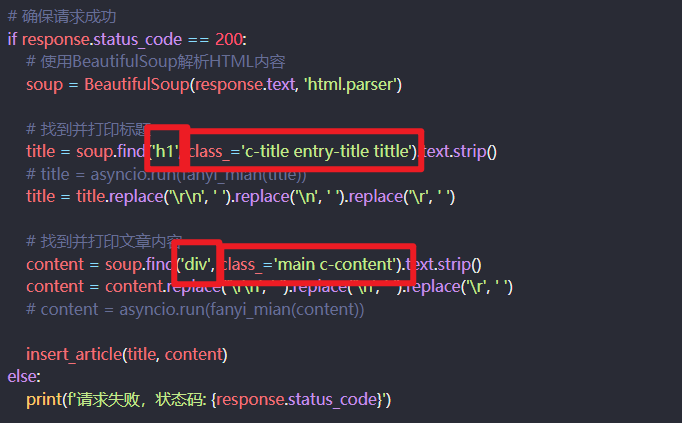
编写配置文件
config.json
{
"host": "10xxxxxxx",
"user": "web_scraping",
"password": "YPxxxxxxxR",
"database": "web_scraping",
"key": "sk-ZB1KxxxxxxxDc6cB5"
}创建数据库(Mysql8.0)
CREATE TABLE IF NOT EXISTS articles (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;之后我们就可以在数据库里面获取到我们的内容了!

采用第三方软件爬取
我们此次演示的是比较简单的爬取方式,可以实现的场景有限,特殊环境需要自己去调整代码。
基于以上的演示,我们提出更加简单的爬取方式:

也就是我们前面提到的采用第三方软件。
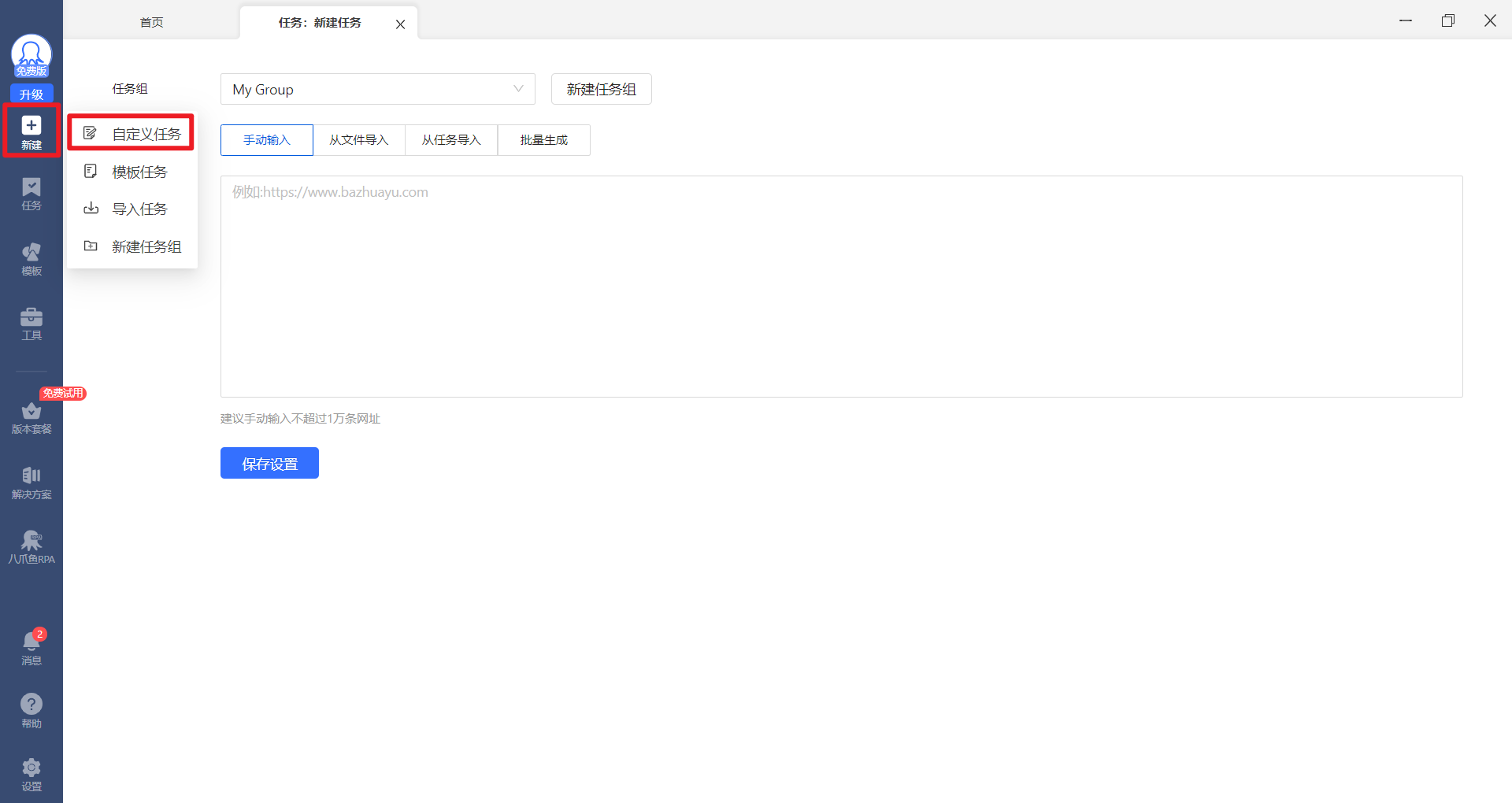
打开我们的自定义任务
之后在【网址】栏里面填写我们需要采集的地址
之后只需要吧你的鼠标放置到标题上,之后右上角的工具栏就可以自动获取内容
选择提取标题的【文本内容】就可以。
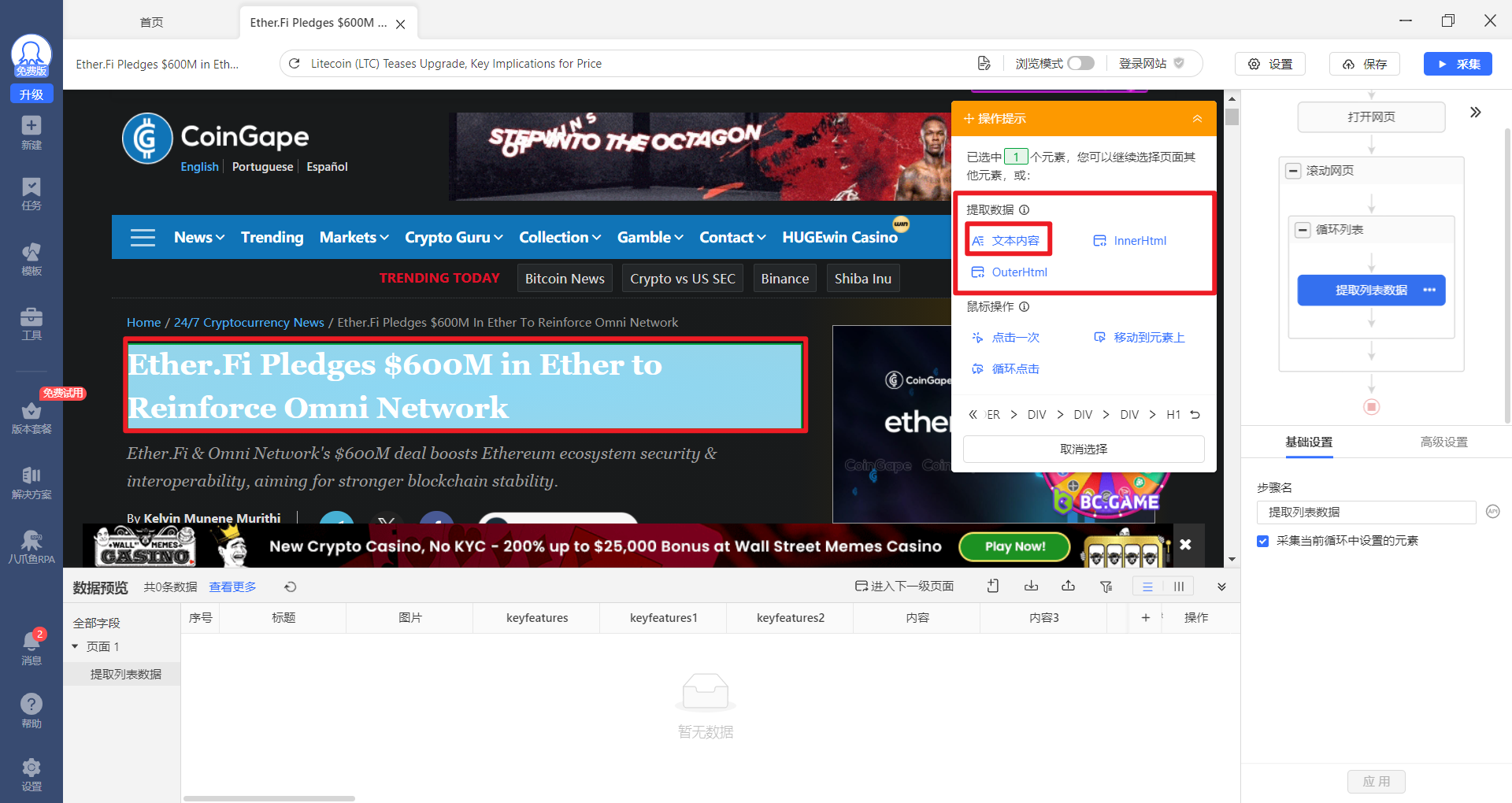
之后内容也是如此。
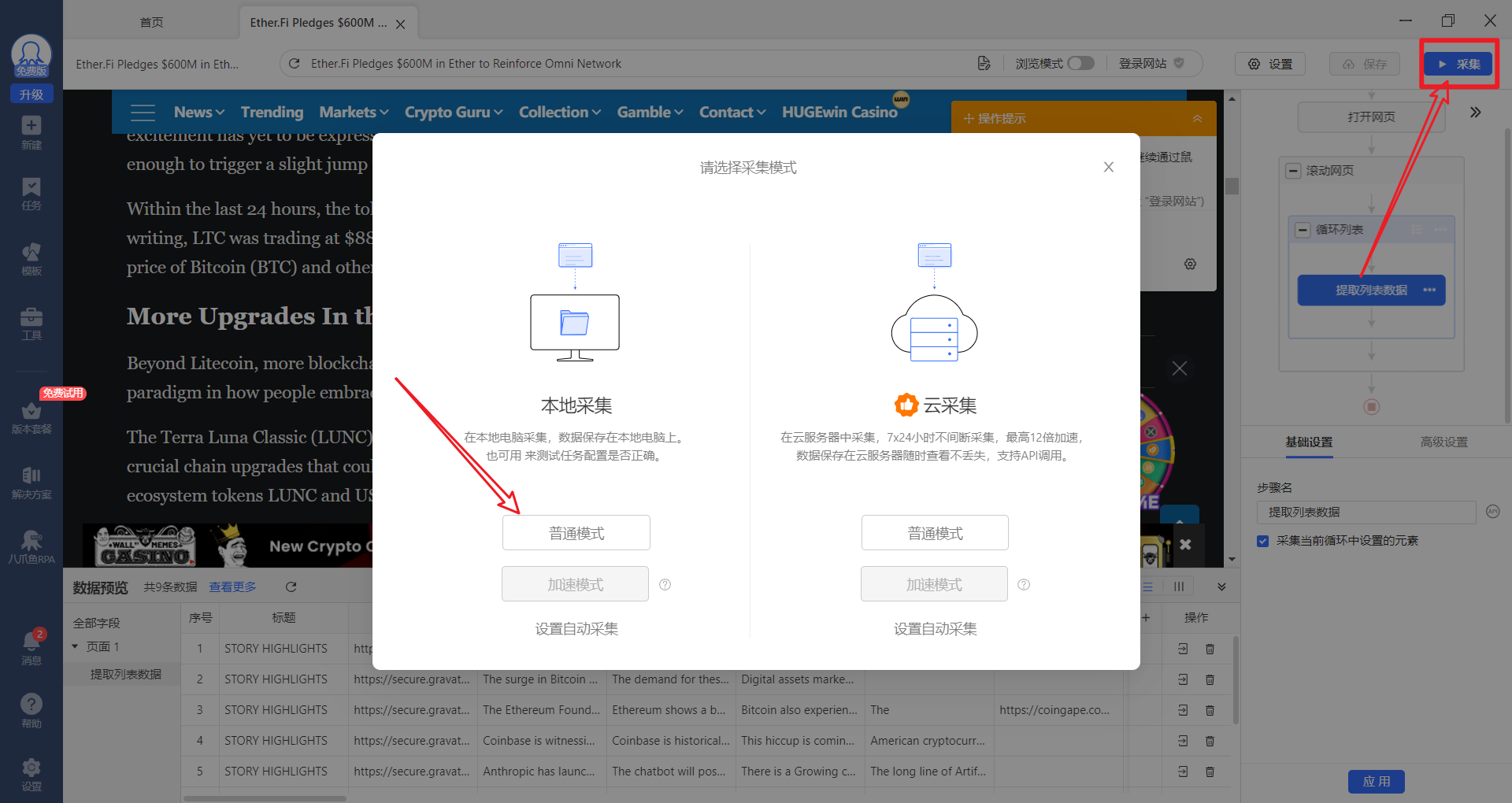
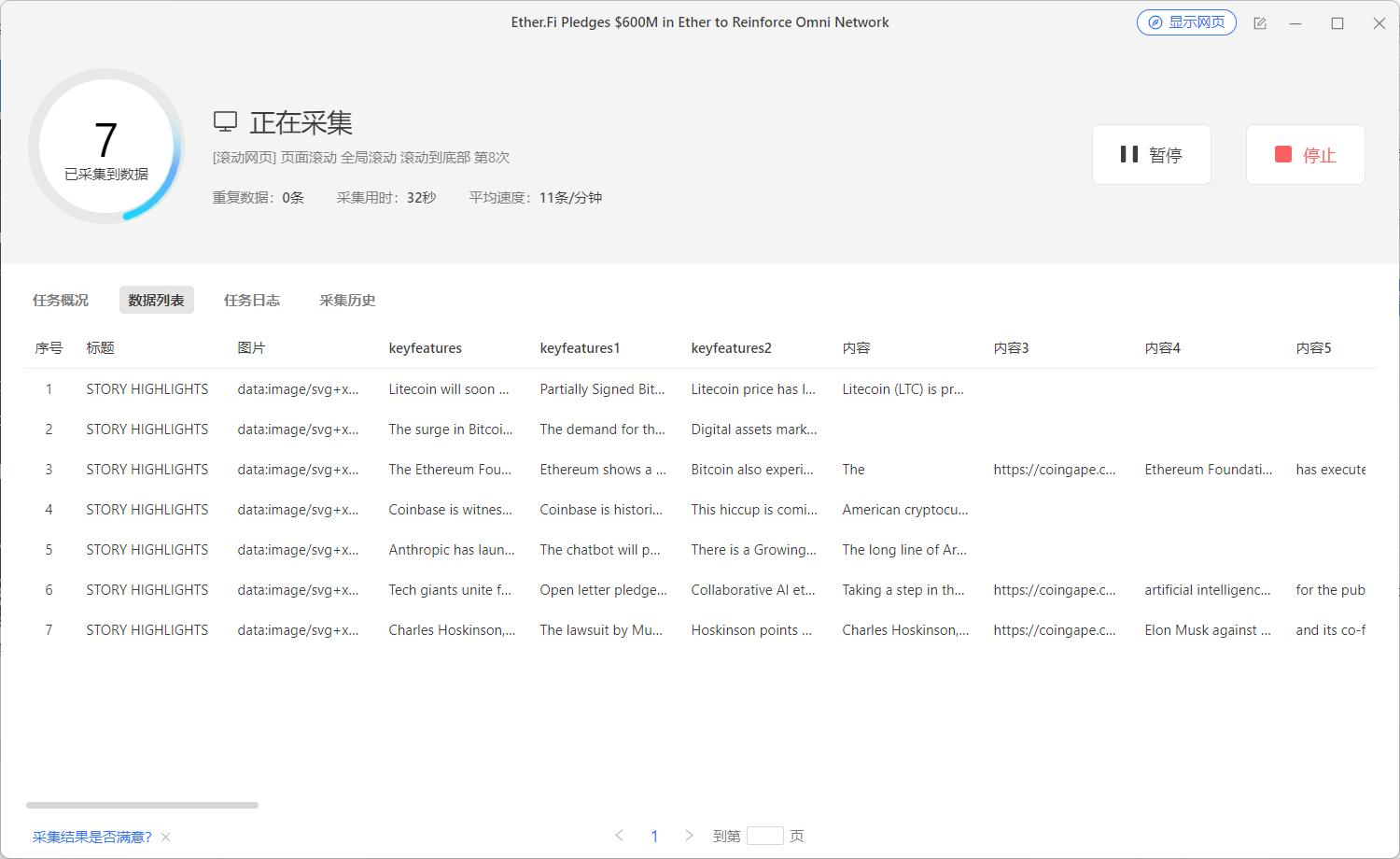
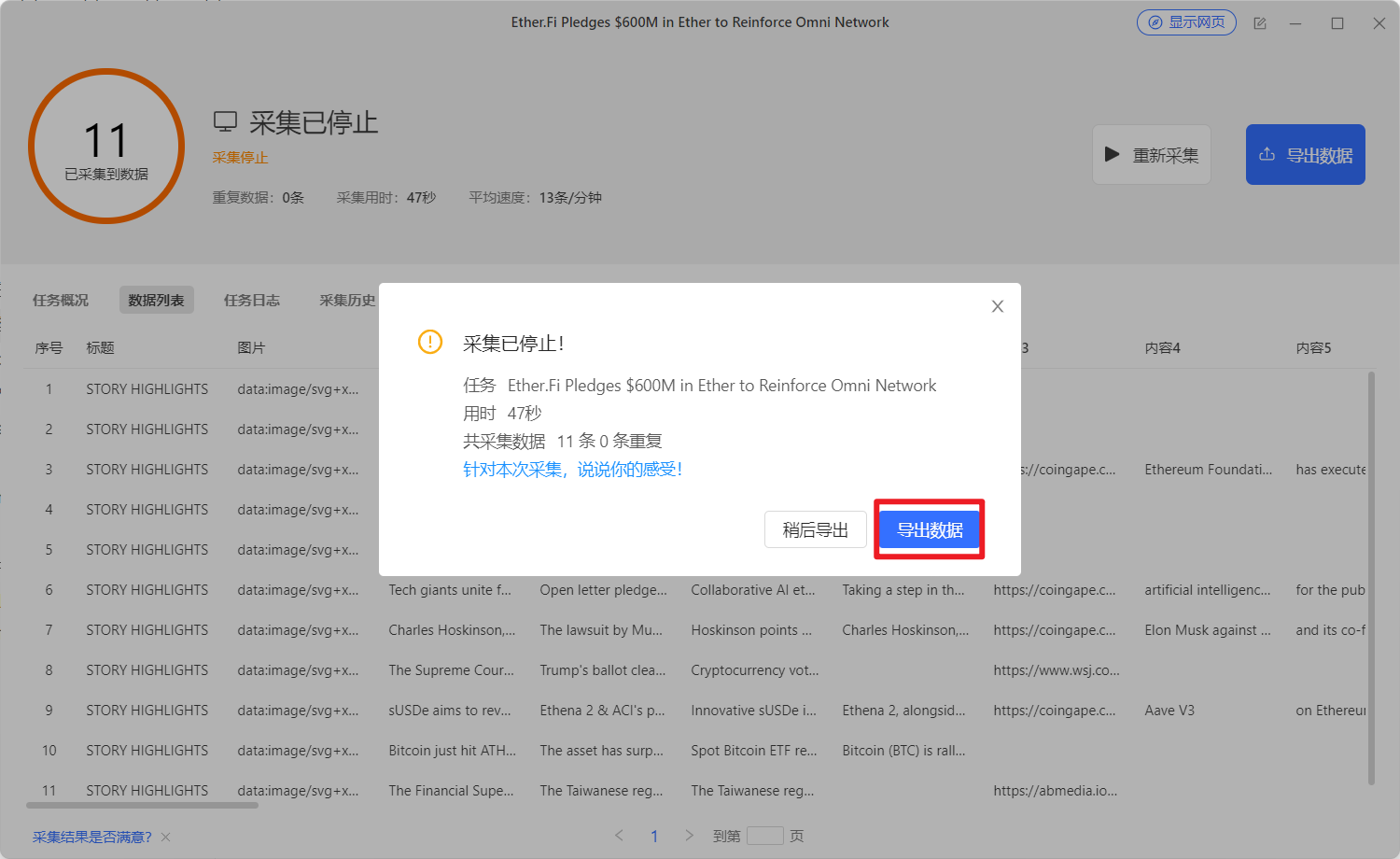
采集完成之后可以把数据导出,连接自己的数据库,之后做导出即可。
这种第三方软件有一定的免费使用频率限制,普通用户基本上满足。